
SHARE
Inteligencia Artificial en la industria: Nuevos servicios y aplicaciones
Actualmente la inteligencia artificial específica basada en visión artificial, tiene la capacidad de la percepción del entorno a través de las imágenes proporcionadas por una cámara, que permite interpretar lo que nos rodea a través del reconocimiento de imágenes, de la misma forma que lo hace nuestro cerebro con la vista.
Inteligencia artificial: Machine y Deep Learning
Escrito por Sergi Palomar
El desarrollo de la IA en este campo va ligado al desarrollo y crecimiento del Big data y del IoT, ya que en la década de los 50, la IA no pudo evolucionar precisamente por no disponer de grandes volúmenes de datos, ni sistemas embebidos con alta capacidad de computación.
Los algoritmos de la IA desarrollan procesos complejos de comprensión, ex- tracción de la información e interpretación de los datos, por lo que disponer de pocos datos y de baja calidad paraliza la estrategia en IA, siendo fundamental que la industria contemple la preparación del dato para su posterior procesamiento, como una fase esencial si se pretenden obtener buenos resultados en términos de predicción y precisión.
Con ello la Industria 4.0 podrá incorporar algunas de las siguientes ventajas competitivas:
- Optimización de tiempo y recursos a través de la automatización de procesos
- Ayuda a la decisión con el incremento de la eficiencia operativa y de la productividad
- Reducción de costes
- Generación de nuevos servicios y aplicaciones
Es necesario destacar las principales diferencias entre Machine Learning y Deep Learning, para una mejor adaptación a la aplicación final, desde detección de patrones, a algoritmos de mantenimiento predictivo, detección de objetos:

Table 1. Diferencias entre Machine Learning y Deep Learning
En el momento que etiquetamos objetos en bibliotecas de imágenes para entrenar una red profunda, se ayuda a la red profunda, a determinar las características del objeto a clasificar. Cada capa tomará como entrada la salida de la capa anterior, aumentando la complejidad y aprendiendo de capa en capa.
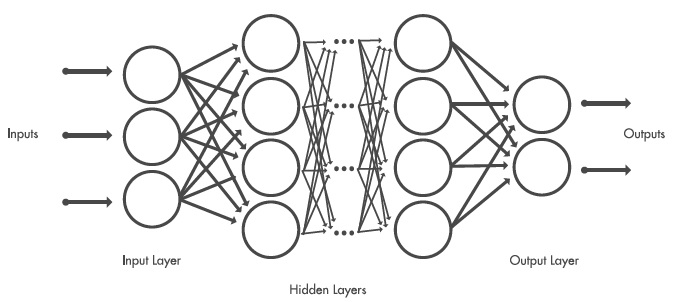
Fig. 1. Ejemplo capas red neuronal
De esta forma, a partir de un set de imágenes de entrada, la CNN aprenderá las características necesarias en sus capas internas, para poder etiquetar los diferentes objetos entrenados en la capa de salida.
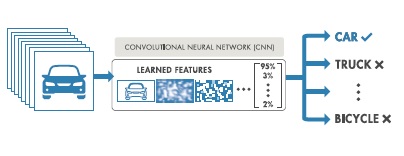
Fig. 2. Etiquetado y clasificación
Por norma general, existe una capa de entrada o input layer, que toma las imágenes, ajusta su tamaño y las pasa a las capas siguientes que se encargan de extraer las características. Las siguientes capas son capas de convolución o convolutional layer las cuales actúan como filtros para las imágenes de entrada encontrando características que servirán más adelante como características para la fase de test. A continuación la capa de pooling conserva la información más relevante o característica dentro de la ventana que permitirá un mejor ajuste de cada característica.
Previa a la capa de salida, está la capa rectified Linear Unit Layer que cambia los valores negativos a cero, para que la CNN permanezca matemáticamente estable. Finalmente la capa final toma las características de alto nivel de las imágenes y las traduce en categorías con etiquetas.
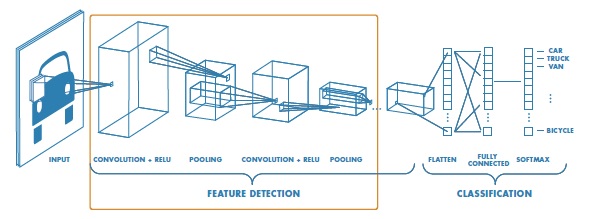
Fig. 3. Capas internas de una CNN
Actualmente, existen distintas soluciones para implementar redes neuronales. A continuación se citan las más relevantes:
- Tensorflow: fue desarrollado por Google Brain Team. Es software libre diseñado para computación numérica mediante grafos.
- Caffe: es un framework de machine learning diseñado con objetivo de ser usado en visión por computador o clasificación de imagenes. Caffe es popular por su librería de modelos ya entrenados (Model Zoo) que no requieren de ninguna implementación extra.
- Microsoft CNTK: es el framework de software libre desarrollado por Microsoft. Es muy popular en el área de reconocimiento del habla aunque también puede ser usado para otros campos como texto e imágenes.
- Theano: es una librería de python que te permite definir, optimizar y evaluar expresiones matemáticas que implican cálculos con arrays multidimensionales de forma eficiente.
- Keras: es una API de alto nivel para el desarrollo de redes neuronales escrita en Python. Utiliza otras librerías de forma interna como son Tensorflow, CNTK y Theano. Fue desarrollado con el propósito de facilitar y agilizar el desarrollo y la experimentación con redes neuronales.
Estas cuatro fases son comunes a todas ellas:
- Entrenamiento: selección red neuronal, preparación del dataset y entrenamiento
- Perfil: Análisis del ancho de banda de la red neuronal, complejidad y tiempo de ejecución
- Depuración: Modificar la topología de la red neuronal para obtener un mejor tiempo de ejecución
- Implementación: Ejecutar la red neuronal customizada sobre un dispositivo Edge.
Aplicaciones
En infraestructuras críticas los sistemas de videovigilancia son un factor clave tanto para la seguridad interna de las instalaciones como para la seguridad de los trabajadores. Debido a la proliferación de herramientas para perfeccionar y entrenar soluciones basadas en visión por computador, también es posible plantear soluciones para monitorizar procesos, pudiendo correlacionar imágenes con otros parámetros provenientes de sensores, datos ambientales, etc. habilitando soluciones más completas ante la detección de eventos.
A modo de aplicación real para Industria 4.0, desarrollé un proyecto el año pasado que presenté en el IoT Solutions World Congress (2018) orientado a la seguridad en infraestructuras críticas. La idea principal, era automatizar el acceso restringido a diferentes áreas del proceso, detectando personas y los diferentes EPIs (Elementos Protección Individual) de forma automática. Esta aplicación estaba destinada a la seguridad preventiva, pudiendo disponer de un registro en tiempo real de PRL (Prevención de Riesgos Laborales).
En un primer paso se descargan las imágenes, a modo de ejemplo, correspondientes al casco de seguridad y al chaleco reflectante como se indica en las siguientes figuras. A priori dos objetos diferentes se convertirán en dos clases, la clase casco y la clase chaleco, que será el objetivo de detección, tanto para la fase de entrenamiento como para la de test. 
Fig. 4. Imágenes descargadas para entrenamiento y test casco seguridad

Fig. 5. Imágenes descargadas para entrenamiento y test chaleco reflectante
Las redes neuronales convolucionales CNN requieren grandes set de datos y elevado tiempo de computación para realizar el entrenamiento. Algunas pueden tomar entre 2 y 3 semanas con combinaciones de GPUs para realizar el entrenamiento. Por lo tanto, en vez de entrenar desde cero, se utiliza el método Transfer Learning o Transferencia de Aprendizaje, donde se utiliza una red ya preentrenada, pero sobre un set de datos distinto, adaptandose al problema a resolver.
Las imágenes deben ser preprocesadas y etiquetadas previamente antes de proseguir con el entrenamiento, con el objetivo de:
- Ecualización de las imágenes, para ajustar el contraste de las mismas
- Conversión del tama ̃no de imágen a 227x227 pixels
- Dividir el dataset original, en dos subdataset para entrenamiento y test (80%-20%) respectivamente
- Creación de las bases de datos LMDB para la evaluación del modelo
Fig. 6. Generación ficheros train.txt y val.txt
A continuación, se calcula la imagen media de los datos de entrenamiento, restando la imagen media de cada imagen de entrada, para que cada píxel tenga un valor cero. Este paso de pre-procesamiento es habitual en el aprendizaje automático supervisado.
Una vez obtenidos los ficheros *.mdb que contienen la información de las imágenes para realizar el entrenamiento, se realiza la compilación del framework de Caffe, para verificar que funciona correctamente. Esta fase de entrenamiento nos permitirá a posteriori realizar la fase de predicción. 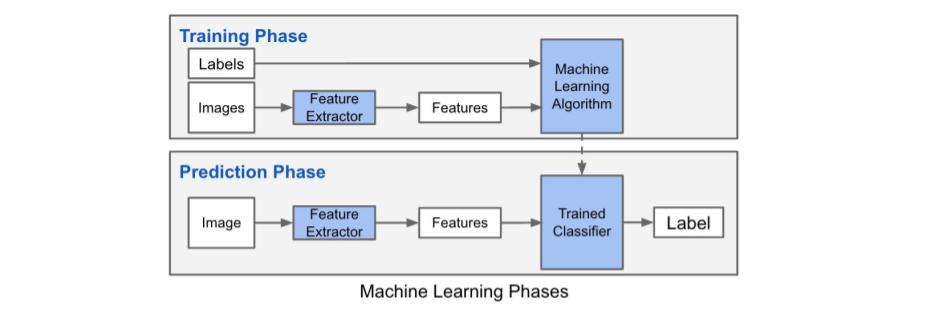
Fig. 7. Diagrama entrenamiento y predicción
Obteniendo después del entrenamiento una red neuronal del tipo: 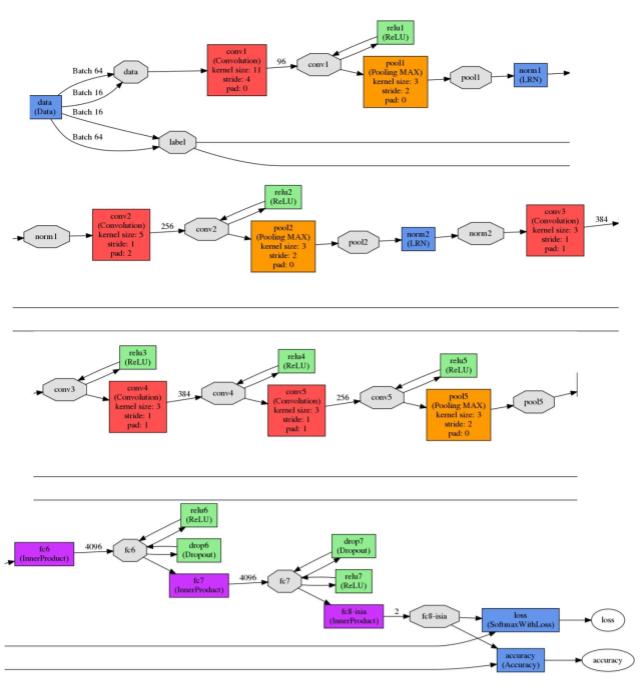
Fig. 8. CNN utilizada en el proceso fine-tune
A través de la API utilizada, que habilita la opción de interactuar con la CNN vía Python, es posible cargar los graph generados y obtener las predicciones sobre los mismos. En las pruebas realizadas, la predicción en portátil (Core I5, 16GB RAM) se efectúa aproximadamente en 80ms, tiempo suficien- temente rápido para aplicaciones como cámaras de seguridad, control, etc. Se detallan varias capturas del software en funcionamiento, con tiempos de predicción inferiores a 100ms. 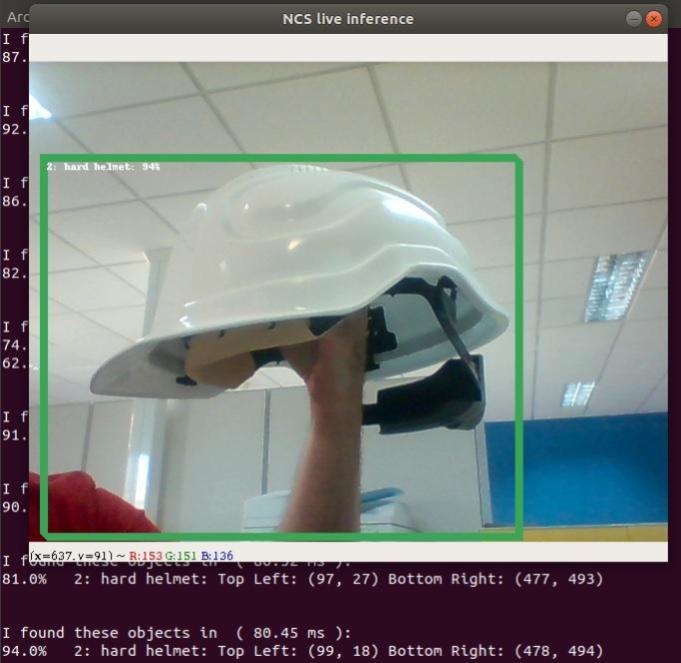
Fig. 9. Detección del casco de seguridad
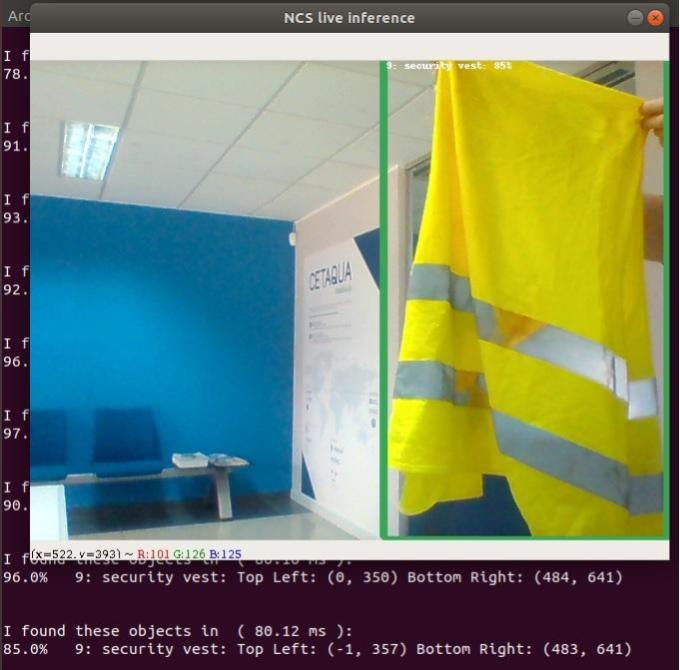
Fig. 10. Detección del chaleco reflectante
Futuro de la IA en la industria
Más de la mitad de las grandes empresas han iniciado ya el despliegue de soluciones de IA, la mayor parte en forma de pilotos y pruebas de concepto, e incluso un pequeño porcentaje afirma haber empezado ya a obtener resultados. Muchas de ellas sin embargo, navegan a la deriva sin una hoja de ruta para IA.
La aplicación directa de detección de objetos mediante técnicas de Deep Learning marcará una diferencia en procesos industriales, sobre todo en aquellos donde la calidad o la producción en cadena requieran mejorar factores como el yield de planta y la eficiencia operativa.

Fig. 12. Ejemplo selección fruta por calidad
También en otros sectores emergentes como UAVs y drones, la integración de VPU (Visual Processing Unit) en sus dispositivos, permite que con la combinación de técnicas de visión por computador y deep learning, el dron sea capaz de captar e interpretar ordenes gestuales, como por ejemplo, acercase o alejarse, realizar una fotografía, activar el vuelo con seguimiento, conocido como follow me.
Con UAVs de mayor tamaño, habilitar la monitorización de campos de cultivo, estudio de la vigorisidad del verde, estado del riego, nivel de cauce de ríos y embalses, control de fronteras, etc. Multitud de aplicaciones que el estado del arte irá permitiendo en los próximos años, donde la IA nos sorprenderá cada vez más, hasta ser transparente al usuario.
Cuéntanos otras formas de aplicar la inteligencia artificial en la industria y descubre qué mas puede hacer ennomotive por ti.
Únete a nuestra comunidad de ingenieros
Sobre el autor
En octubre de 2018, ennomotive lanzó un desafío que buscaba una solución precisa y robusta para detectar y medir el polvo que se produce en entornos industriales.
Durante 6 semanas, 43 ingenieros de 20 países participaron en el desafío y entregaron diferentes soluciones. Tras una minuciosa evaluación, las soluciones que mejor cumplían los criterios de evaluación eran obra de Manuel Caldas, de Uruguay, Maksym Gaievsky, de Ucrania, y Sergi Palomar, de España.
Sergi Palomar, Investigador Ing. Superior Telecomunicación y Electrónico, Máster en IA y MBA, ha escrito un artículo en el que comparte sus conocimientos los nuevos servicios y aplicaciones de la inteligencia artificial (IA) en la industria.
Referencias
- Google works with movidius to deploy advanced machine intelligence on mobiles. Biometric Technology Today 2016, 2 (2016), 12.
- Campos, V., Jou, B., and i Nieto, X. G. From pixels to sentiment: Fine-tuning cnns for visual sentiment: Image and Vision Computing 65 (2017), 15 – 22. Multimodal Sentiment Analysis and Mining in the Wild Image and Vision Computing.
- Gu, J., Wang, Z., Kuen, J., Ma, L., Shahroudy, A., Shuai, B., Liu, T., Wang, X., Wang, G., Cai, J., and Chen, T. Recent advances in convolutional neural networks. Pattern Recognition 77 (2018), 354 – 377.
- Jain, N., Kumar, S., Kumar, A., Shamsolmoali, P., and Zareapoor, M. Hybrid deep neural networks for face emotion recognition. Pattern Recognition Letters (2018).
- Józwiak, L. Advanced mobile and wearable systems. Microprocessors and Microsystems 50 (2017), 202 –221.
- Li, D., Deng, L., Gupta, B. B., Wang, H., and Choi, C. A novel cnn based security guaranteed image watermarking generation scenario for smart city applications. Information Sciences (2018).
- Lu, K., An, X., Li, J., and He, H. Efficient deep network for vision-based object detection in robotic applications. Neurocomputing 245 (2017), 31 – 45.
- Lu, K., Chen, J., Little, J. J., and He, H. Lightweight convolutional neural networks for player detection and classification. Computer Vision and Image Understanding (2018).
- Sharma, N., Jain, V., and Mishra, A. An analysis of convolutional neural networks for image classification. Procedia Computer Science 132 (2018), 377 – 384. International Conference on Computational Intelligence and Data Science.